
Does Latency Kill AI Agents?
Why Telecom is Confusing the Latency of Chatbots with the Compounding Demands of Agentic Loops


There is massive confusion in the Telecom sector regarding what an AI agent actually is, how it functions, and the type of network infrastructure it requires. The industry has lazily reduced the entire debate to a binary choice: either put an expensive GPU at the network edge, or keep it in the cloud?
The reality is far more complex and dangerous.
The shift from human-triggered chatbots to autonomous, machine-speed agents is triggering a structural latency crisis that completely rewrites network economics. For Telcos and cloud providers alike, solving this architectural challenge will determine who captures the premium token value of the Inference Economy and who gets relegated to selling low-margin data pipes.
The Chat Clock vs. The Agent Clock
Most generative AI applications operate on a human timescale. When a user enters a prompt into a chatbot, the data packet travels to a centralized cloud server and back. This single cross-country trip takes about 100 milliseconds. Because human users cannot perceive a delay that small, the physical distance to the cloud server is not a problem.
AI agents function differently. Instead of waiting for a single human prompt, they execute automated, continuous loops: perceiving data, reasoning, making decisions, and taking action across multiple systems.
This continuous loop changes the math of network latency. A single enterprise task, such as an automated fraud check or a dynamic supply chain adjustment, can require up to 50 sequential machine-to-machine calls to complete the workflow. If an agent relies on a centralized cloud, each of those 50 calls incurs a transit delay. If each trip takes 100 milliseconds, the agent spends 5 seconds simply waiting for data to travel over the internet.
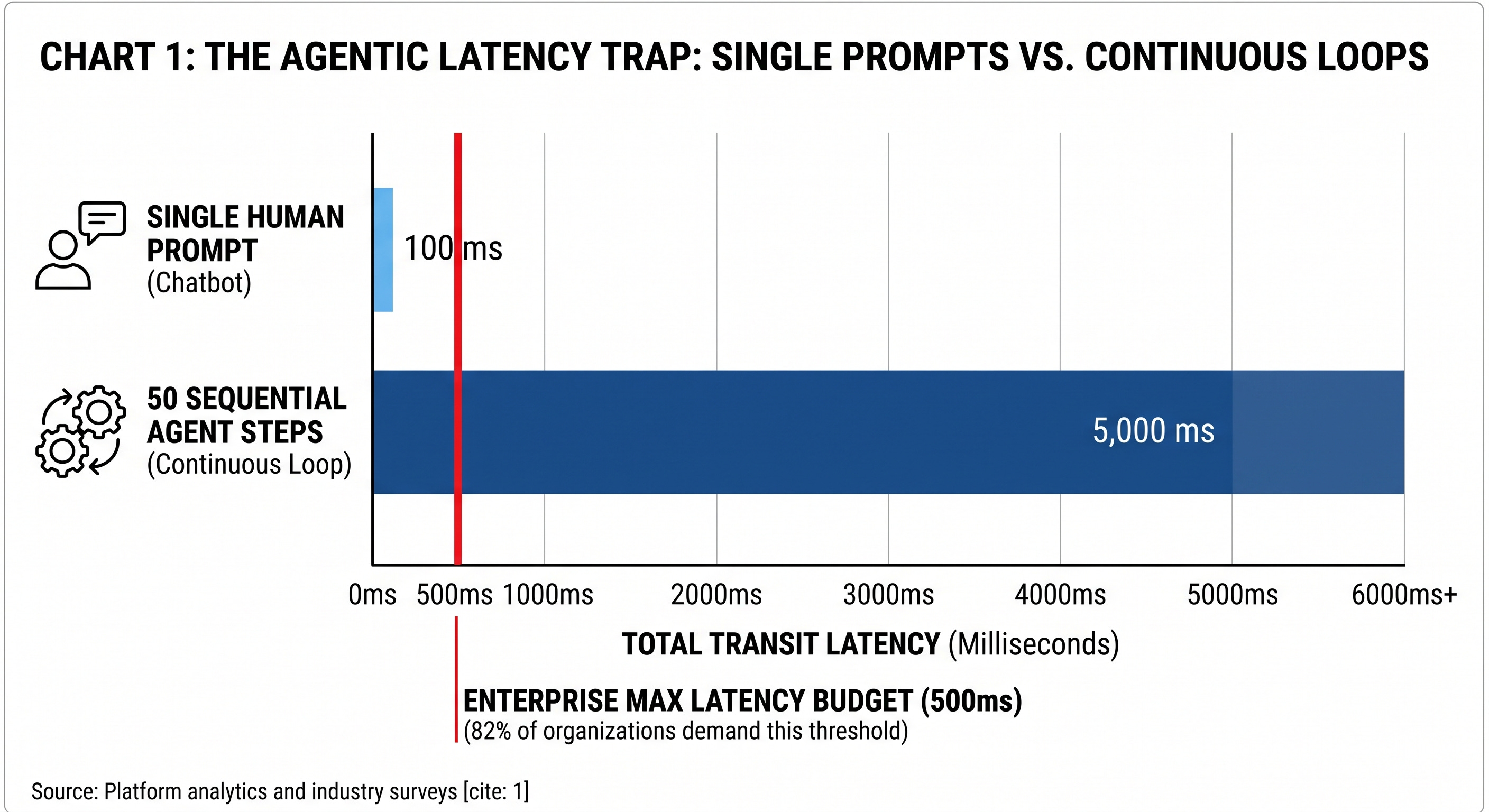
That compounding delay breaks technical business requirements. Research indicates that 82% of organizations mandate that an entire multi-step workflow finishes in 500 milliseconds or less. Furthermore, 64% of operators are actively targeting total execution times of 250 milliseconds or less.
Five seconds of network transit time makes a 500-millisecond budget impossible. Platform analytics show that introducing as little as 10 to 15 milliseconds of added delay to these loops causes high-value automated workflows to fail or increases user abandonment. To keep a 50-step workflow under a 500-millisecond limit, the compute hardware must sit close enough to the data source to virtually eliminate transit time.